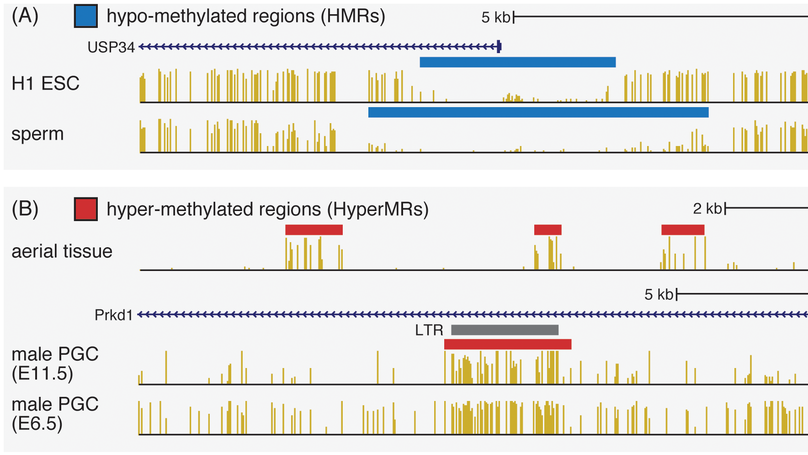
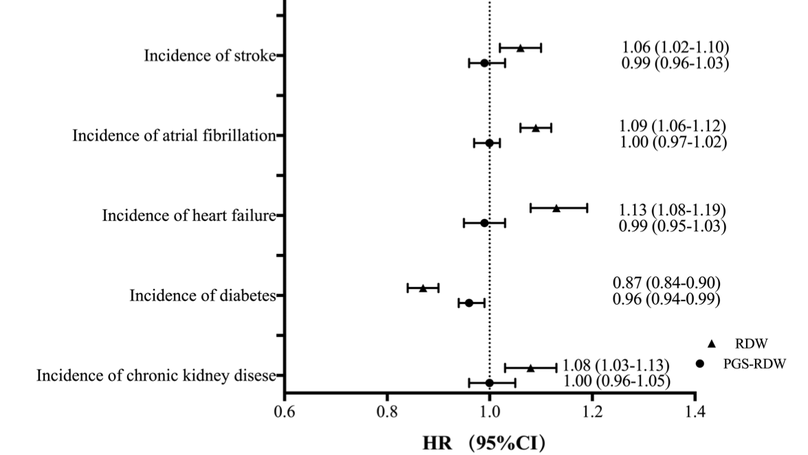
Publications


Clonal haematopoiesis involves the expansion of certain blood cell lineages and has been associated with ageing and adverse health outcomes1,2,3,4,5. Here we use exome sequence data on 628,388 individuals to identify 40,208 carriers of clonal haematopoiesis of indeterminate potential (CHIP). Using genome-wide and exome-wide association analyses, we identify 24 loci (21 of which are novel) where germline genetic variation influences predisposition to CHIP, including missense variants in the lymphocytic antigen coding gene LY75, which are associated with reduced incidence of CHIP. We also identify novel rare variant associations with clonal haematopoiesis and telomere length. Analysis of 5,041 health traits from the UK Biobank (UKB) found relationships between CHIP and severe COVID-19 outcomes, cardiovascular disease, haematologic traits, malignancy, smoking, obesity, infection and all-cause mortality. Longitudinal and Mendelian randomization analyses revealed that CHIP is associated with solid cancers, including non-melanoma skin cancer and lung cancer, and that CHIP linked to DNMT3A is associated with the subsequent development of myeloid but not lymphoid leukaemias. Additionally, contrary to previous findings from the initial 50,000 UKB exomes, our results in the full sample do not support a role for IL-6 inhibition in reducing the risk of cardiovascular disease among CHIP carriers. Our findings demonstrate that CHIP represents a complex set of heterogeneous phenotypes with shared and unique germline genetic causes and varied clinical implications.
Related Scientific Presentation – YouTube